谷歌旗下AI开发部门DeepMind的作品登上了最新一期的《Science》杂志的封面。AlphaZero在围棋和日本将棋领域里超越了人类之后,又从无到有地重新挖掘出了国际象棋的正确下法。研究人员公布了通用算法和测试数据。
2017年末,我们推出了AlphaZero,这是一个独立的系统,从头开始自行学习国际象棋、将棋(日本版的国际象棋)和围棋,最终在每个领域内击败世界冠军程序。我们对初步结果感到非常兴奋,并很高兴看到国际象棋界的回应,他们在AlphaZero的棋谱中看到了一种突破性的、高度动态的和“非传统的”行棋风格,与之前的任何国际象棋游戏引擎不同。
今天,我们非常开心能够向公众发布AlphaZero的完整评估。报告发表在Science(开放访问版本)杂志上。该期刊确认了这些初步结果。它描述了AlphaZero如何快速学习每个游戏,成为历史上最强大的玩家,从随机游戏开始自我训练,没有内置任何知识,唯一需要预先输入的就是游戏的基本规则。
国际象棋世界冠军Garry Kasparov卡斯帕罗夫也在《科学》上撰文表示,“我无法掩饰自己的满足感,它充满了非常有活力的风格,就像我一样!”。他指出,这种从头开始每个游戏的能力,不受人类游戏规范的约束,产生了独特的、非正统的、但具有创造性和动态的游戏风格。AlphaZero的棋风可能更接近本源。“它以一种深刻而有用的方式超越了人类。”
国际象棋大师Matthew Sadle和女性国际大师Natasha Regan已经分析了AlphaZero数以千计的棋谱。Matthew指出,它的风格不同于任何传统的国际象棋引擎。“这就像在翻阅过去一些伟大棋手的秘籍。”
传统的国际象棋引擎——包括世界计算机国际象棋冠军Stockfish和IBM突破性的Deep Blue——依赖于数千个由强大的人类玩家手工编制的规则和启发式算法,试图解读游戏中的每一种可能性。 Shogi程序也是针对于特定游戏的,使用与国际象棋程序类似的搜索引擎和算法。
AlphaZero采用了一种完全不同的方法,用深度神经网络和通用算法取代了这些手工制作的规则,这些算法对基本游戏规则之外的东西一无所知。
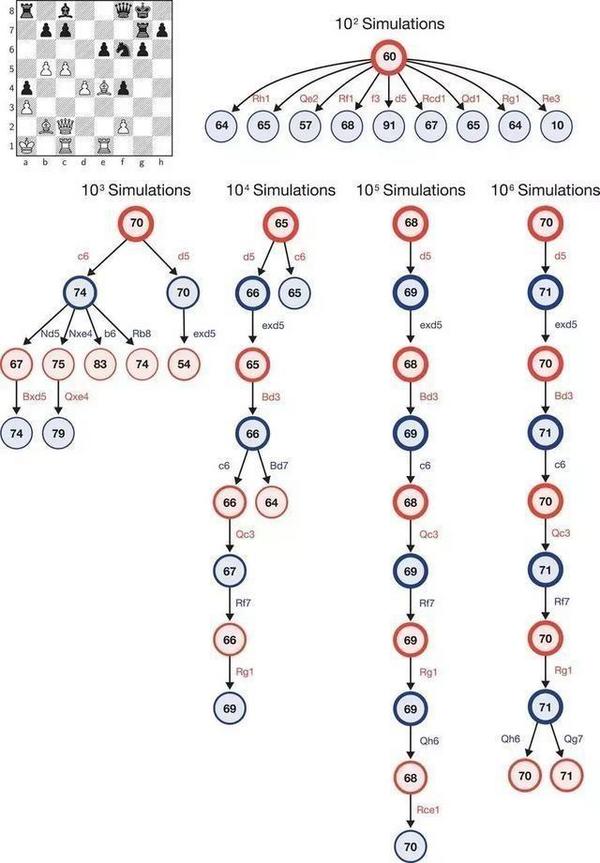
论文中举例的决策树
国际象棋:AlphaZero训练4小时就超越了世界冠军程序Stockfish;
日本将棋:AlphaZero训练2小时就超越了世界冠军程序Elmo;
围棋:AlphaZero训练30小时就超越了传奇性的AlphaGo。
为了掌握每一种游戏,未经训练的神经网络通过被称为强化学习的试错过程自我对弈数百万盘。起初,它完全随机落子,但随着时间的推移,系统从每一盘的胜负得失中吸取经验,调整神经网络的参数,选择出更加正确的一步。网络需要的训练量取决于游戏的风格和复杂程度,国际象棋大约需要9个小时,将棋大约需要12个小时,围棋则用了13天。
AlphaZero能够掌握三种不同的复杂游戏——或许应该说是,任何开放信息的游戏——是走向最终实际应用的重要一步。它表明单个算法可以仅仅从最基本的规则中,发展出一整套超越人类千年积累的知识体系。而且,尽管还处于早期阶段,AlphaZero的创意见解加上我们在AlphaFold等其他项目中看到的令人鼓舞的结果,让我们对完成创建通用学习系统的使命充满信心。我们可以用它来解决最重要和最复杂的科学问题。
数据加载中...BIU...BIU...BIU...