物理学家们借鉴物理学方法研究语言,形成了语言动力学这一交叉学科。该领域的研究不仅能帮助我们理解语言的传播和演化,还能为保护濒危语言提供帮助。
语言的传播、演化、竞争和灭绝,这些现象与生物物种惊人地相似。为了理解这些机制,物理学家们正将他们的方法应用于语言学,由此诞生了一个交叉学科——语言动力学。下面,我们将由 Marco Patriarca、Els Heinsalu 和 David Sánchez 来为大家解释这一领域的研究。
如果把研究界比作一个生态系统,那么不同学科的科学家就相当于其中的物种。物理学家们多年来一直将他们的方法和工具应用于其他领域,不仅渗透了其他自然科学,也扩展到了社会科学领域。
由此诞生了一些交叉学科,例如社会物理学和经济物理学,它们将物理学中的数学模型应用于社会情境,比如交通、人群和金融市场等。这些新领域及其所涉及的模型,都属于复杂系统理论的一部分。复杂系统由许多相互作用的要素组成,这些要素共同产生集体的行为,而这种行为如果只孤立地考虑单个要素的属性,就无法理解。
社会物理学和经济物理学如今已得到广泛认可,但将物理学应用于语言学(即语言动力学)这一领域则鲜为人知。事实上,我们甚至遇到过一些审稿人质疑物理学家从事语言学研究的严肃性。那么,如果你是这样一位特立独行的物理学家,正致力于研究传统上属于语言学范畴的问题,你会作何反应呢?好吧,咒骂是一种选择。
散播话语
脏话实际上是物理学方法如何应用于语言学的一个绝佳例子。2011 年,丹麦玻尔研究所和日本九州大学的一组物理学家们研究了日本脏话如何在全国传播(《物理评论快报》 83卷066116号)。这是一个相对简单的场景,因为它没有涉及语言的复杂性,例如语法、句法或语音方面的影响。这仅仅是一个词语如何传播的问题,非常类似于标准扩散过程。此外,日本列岛细长扁平的形状使其地形近似于一维,从而大大简化了扩散过程。
这项研究分析了 21 个脏话的语言地图(由过去的调查构建),结果显示,大部分脏话都是从京都市传播出去的,京都市通常被认为是日本的文化中心。事实上,研究的大部分脏话都位于京都市南北方向的波锋上,这些波锋的距离大致相等(图 1)。

图 1
研究人员通过使用一个简单的文化扩散模型(语言创新会在所有方向随机扩展,直到遇到并可能取代(以一定概率)旧的创新),不仅能够复制这 21 个脏话的空间分布,还能复制连续波锋之间的可变距离。
例如,图 1 显示脏话“aho”(笨蛋)主要在京都使用,而“baka”(蠢人)则在首都东京更常见。这种差异是由于京都地区在不同时间出现语言创新的传播所致,而不是东京和京都这两个大城市之间的文化竞争。换句话说,“baka” 过去也曾在京都使用,但后来被新出现的“aho” 所取代,而“aho” 目前还没有传到东京。
类似于典型的反应扩散波锋的场景也出现在生态学中,例如一个物种殖民新领地或入侵另一个物种已占领的区域。事实上,语言动力学和生态学之间存在许多数学上的相似性。
传播与演化
除了词语和惯用语之外,语言特征(例如语音特征和不同的句法结构)也可以传播。这种传播过程可以在人群内部发生,即语言社群中出现语言创新;也可以在拥有不同语言的社群之间通过接触发生。语言传播并不一定与人类迁徙有关。语言作为一个整体的传播通常伴随着语言社群的迁徙,即说某种语言的人们从一个地方搬到另一个说另一种语言的地方。结果,该地区可能形成双语社区,甚至原始语言可能会灭绝。
此外,语言传播通常与语言演化并行发生,甚至可能导致语言分裂成方言。这类似于生物学中发生的情况,即物种中的一个群体与其他成员分离,发展出自己的特征并成为一个新物种。
例如,马萨特克语系是生活在墨西哥东南部瓦哈卡州北部地区约 24 万人使用的密切相关的土著语言群。这是一个重要的案例研究,因为马萨特克语系在小范围内表现出与欧洲的罗曼语族(包括法语、西班牙语意大利语)等大型语言群相当的水平的多样性和复杂性。
当马萨特克人从他们的家园迁徙时,他们首先在低地传播,然后迁徙到马萨特克山脉的各个山谷。奇怪的是,一些低地使用的语言与山地使用的语言更相似,而不是与地理上更接近的其他低地语言更相似。
为了解释这一现象,2019 年的一项研究(由作者 Marco Patriarca 和 Els Heinsalu 参与)使用了一个简单的传播演化模型(《语言和传播科学中的复杂性应用》10.1007/978-3-030-04598-2_9)。研究表明,低地地理的二维特征使得语言传播速度更慢,因此观察到更大的多样性,因为突变出现和传播的时间更充裕。相比之下,连接低地和山脉的山谷的准一维特征迫使语言更快地传播,从而阻止了突变。
语言传播和演化的另一个有趣例子涉及努米克语系,这是美国西部美洲原住民使用的七种语言的统称。在这一案例中,人们认为原始努米克语在努米克人的家园(内华达山脉南部和死亡谷)演化为多个变种。然后,当努米克人开始在更大的盆地地区迅速传播时,它形成了不同语言的扇形分布(图 2a)。
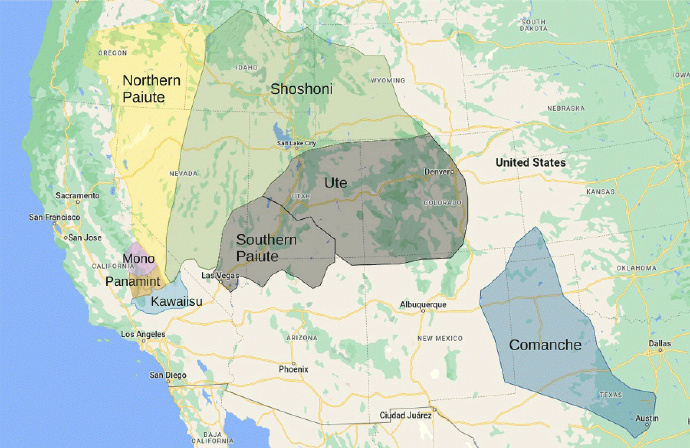
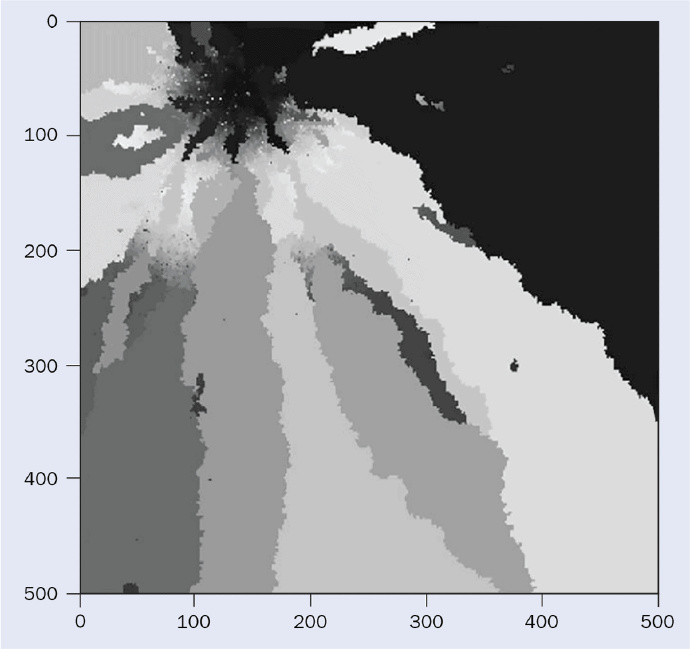
图 2a/b:美国西部的美洲原住民所讲的七种努美克语,从努美克人的家园开始,以扇形分布的方式跨越大盆地,如图(a)所示,这是一张根据实地数据绘制的地图。巴西伯南布哥联邦大学的一个研究小组使用一个同时描述语言扩散和进化的最小模型再现了这种结构(b)。
2006 年,巴西联邦伯南布哥大学的研究人员使用计算机模拟成功地复制了这一模式(《物理学 A》361 期 361 页)。他们使用了一个人口在领土上繁殖和扩张的最小模型,结果表明,该人口的语言会发生变化并分裂成不同的语言,最终导致语言的空间分布与努米克语案例观察到的相似(图 2b)。
竞争与演化
语言演化是语言动力学中一个重要而复杂的方面。相应的数学描述主要来自于生态学和遗传学演化模型,但也包括社会科学中使用的模型,例如博弈论。一些语言演化模型是抽象的,侧重于演化过程的统计规律,而另一些模型则考虑了语言学中已知的规则,例如描述声音演化的语音规律。
然而,在短时间尺度上,我们可以忽略演化,并将语言视为竞争说话者的固定物种。在语言竞争中,这是语言动力学中最早讨论的主题之一,我们不仅仅有两个竞争物种,即说语言 A 或 B 的单语者。相反,还存在双语者,他们可以同时说两种语言。那么,语言是否可以比作一种寄生虫,可以与另一种寄生虫在宿主体内共存?
另一种解释是,说话者是时间网络中的节点,说话者用来交流的语言是两个节点之间的链接。现在,如果我们有一个多语言社区,说话者必须决定在何处、与谁以及为何使用哪种语言。为了理解少数语言如何根据说话者的选择而存活或灭绝,我们可以使用语言使用模型,并可能纳入来自真实情况的信息(《公共科学图书馆·综合》16 期 e0252453)。
收集语言信息
传统上,人们通过实地考察来收集有关自然语言(即人类通过说话而自然形成的语言)的信息,马萨特克语和努米克语的研究就是这种情况。这涉及采访说话者以记录语言,重点是口语而不是书面文本。然后,可以使用不同的数学方法和工具对数据进行统计分析,以估计语言之间的语言距离并揭示语言群。
然而,书面文本提供了另一种看待语言的视角,这也是物理学家可以参与的语言学另一个分支。通过应用统计物理学,可以揭示规律和统计规律,例如齐夫简短定律,该定律指出使用频率更高的词语往往更短。如今,这类研究可以使用数值工具和快速计算机进行,从而轻松分析大型数字数据库。通过这种方法,简短定律已被证明适用于来自 80 个不同语系的大约 1000 种语言。
社交媒体的兴起也为收集语言数据开辟了新的途径。例如,Twitter 上的人们进行实时交流,以数百万条来自世界各地且包含多种语言的地理标记帖子形式提供了大量数据。这类数据可能存在一定的偏差,因为用户主要是年轻人(12-34 岁)和男性,但它们确实包含许多有趣和令人着迷的信息。
在一项最近的研究中,西班牙跨学科物理和复杂系统研究所(IFISC)的物理学家们构建了不同多语言地区的高分辨率语言图景,以捕捉这些社会的多样性并理解导致语言灭绝的原因(《物理评论研究》3 期 043146 页)。为此,他们使用了一个包含 1 亿条推文的数据集,这些推文是在 2015 年至 2019 年间在 16 个国家和地区收集的。语言和位置的归属是自动完成的,Twitter 提供了位置,研究人员使用自动工具来确定语言,这使得研究团队能够计算给定语言和地理位置中说话者的比例。

图 3:比利时(上)和加泰罗尼亚(下)都是多语言地区,包含单语社区。通过分析2015年至2019年期间收集的推文,研究人员能够计算出两国100平方公里区域(广场)内使用特定语言的人口比例。这些地图显示了(a)法语,(B)荷兰语,(c)加泰罗尼亚语和(d)西班牙语使用者的比例,其中深紫色表示没有使用该语言的人,黄色表示仅使用该语言的地区。黑色意味着该地区的推文不足以构成数据集。在比利时,北部以荷兰语为主的弗兰德斯地区和南部以法语为主的瓦隆地区之间存在明显的语言鸿沟。大多数语言混合发生在边界(由黑线表示)。布鲁塞尔也被标记在地图上,并显示了讲法语的人的集中。相比之下,加泰罗尼亚的地图显示了更广泛的混合,中部农村和东部沿海大城市之间略有差异。
研究发现,包括比利时或瑞士在内的国家拥有被明确界限分隔的单语社区,而在加泰罗尼亚等地区,各种语言的说话者似乎混杂在一起(图 3)。这些不同分布的原因主要是历史性的,但也与语言相似性和声望有关。
推文还可以提供有关地理词汇变异的有价值信息,即在不同地区使用不同的词语和短语来指代同一事物。一种方法是为同一定义创建词语变异列表,并使用聚类算法研究它们的时空分布。通过寻找具有给定词汇特征的要素之间的相似性以及观察它们如何形成聚类,可以找到方言区。或者,人们可以考虑数据集中的所有词语,而不仅仅是那些显示出替代形式的词语。
在最近的一项研究中,IFISC 的研究小组使用第二种方法绘制了美国文化区域的图(《人文与社会科学交流》10 期 133 页)。基于文化归属可以从人们讨论的话题中推断出来的想法,研究人员考察了地理标记推文中词语的频率分布,以找到它们的区域热点。从那里,他们能够推导出主要的主题变异群集(图 4)。

图 4:通过查看2015年至2021年在美国发布的90亿条带有地理标记的推文的内容,研究人员能够构建单词的频率分布,以找到与其使用相对应的区域热点。从这些单词以及人们讨论的话题中,团队能够绘制出文化区域(a)。每个部分是一个县,那些涂白色的没有足够的数据。不同地区最常讨论的话题是:美食、时尚、音乐(蓝色);体育、学校(黄色);自然、天气、户外活动(绿色);城市生活、移民、暴力(红色);自我参照、西班牙文化(青色)。每个区域的最具体的词显示在(B)中。
虽然这类社交媒体数据研究可以提供短期内的语言图景,但未来的挑战将是追踪语言及其竞争如何随着时间的推移而演化。然而,在这样做时,我们必须记住,语言在现实生活和网络上的使用方式可能有所不同。大多数网络信息都是英文的,但在现实生活中,它只是第三大母语,而中文则更为常见(尽管它只占网络语言的不到 2%)。此外,许多现存语言在网络交流平台上根本没有体现。
本文译自 Physics World,由 BALI 编辑发布。