科学家用AI辅助,首次实现银河系的全尺度逐颗恒星模拟,粒子数达3000亿,突破了过去只能处理不到10亿粒子的瓶颈,速度提升上百倍。
科学家用AI辅助,首次实现银河系的全尺度逐颗恒星模拟,粒子数达3000亿,突破了过去只能处理不到10亿粒子的瓶颈,速度提升上百倍。(48字)
银河系有几千亿颗恒星,包围在暗物质晕中,还有气体在盘里旋转。恒星内部合成重元素,大质量恒星寿命短,结束时会超新星爆炸,把元素和巨大能量喷到周围气体里。这些气体混合后,又形成新一代恒星。这个循环持续上百亿年,造就了今天的银河系,也包括地球和我们。
要用电脑重现这个过程,就得同时算重力、气体流动和化学反应。过去的方法用N体模拟处理恒星和暗物质,用光滑粒子流体力学处理气体。但问题出在超新星爆炸上:爆炸区气体温度高、变化快,需要极短的时间步长来计算,否则结果不准。这一步长有时只有几年,却要模拟整个银河系上亿年的演化,整个系统就被拖慢了。
以往最好的银河系模拟,粒子总数不到10亿,单个恒星或气体团的质量至少几百个太阳质量,根本分不清单颗普通恒星。小型矮星系才能勉强做到逐颗恒星级别,但那只有银河系的几百分之一。
瓶颈就是超新星。爆炸后,气体壳层膨胀只需几年,但银河盘转一圈要上亿年。时间尺度差了太多,传统方法只好给不同区域不同步长,或干脆降低分辨率。
日本团队想出一个巧办法:别一步步算爆炸过程,用深度学习做“代理模型”来跳过它。
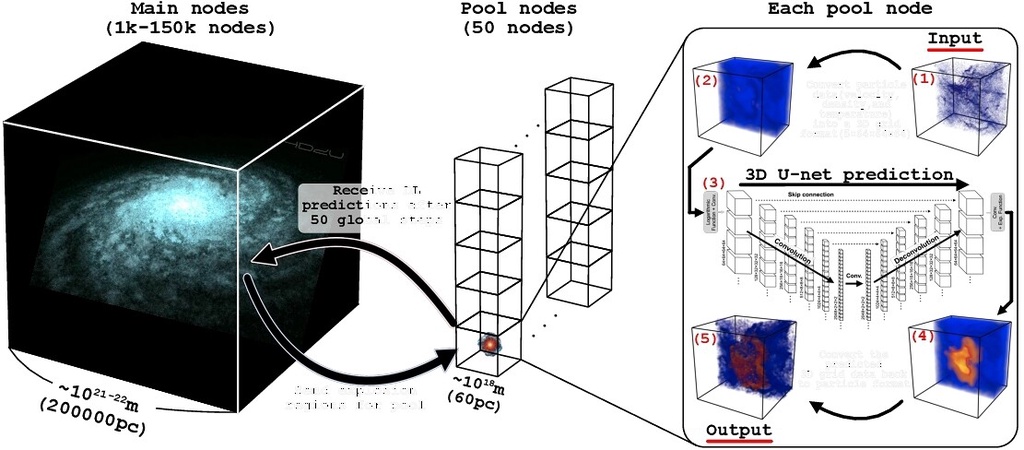
他们把计算节点分成两组。大组负责整个银河系的正常演化,用统一的较长步长(2000年)。一旦侦测到某颗大质量恒星要爆炸,就把爆炸点周围60秒差距(约200光年)的一个小立方体里的气体粒子数据,扔给少数几个“池节点”。
池节点上的神经网络已经提前用大量高分辨率单次超新星模拟训练好。它直接预测10万年后这个区域的气体会变成什么样,包括密度、温度、速度和金属丰度。然后把结果塞回主模拟。
主计算完全不等,继续往前走。多个超新星同时发生也没事,因为池节点可以并行处理。这样,爆炸不再拖后腿。
他们在富岳超级计算机上跑满了95%的节点(14.89万个节点,714万核),粒子总数达到3000亿。暗物质、恒星和气体的质量分辨率都接近1个太阳质量,真正实现了银河系的逐颗恒星模拟。
性能也很亮眼。一时间步只需20秒左右,模拟100万年只要几小时。相比传统方法,他们的速度快了113倍,粒子数多了几百倍。
这个方法不只适用于银河系。任何需要同时处理极大和极小尺度的问题,比如宇宙大尺度结构形成、黑洞吸积盘、天气预报或湍流模拟,都能用类似代理模型提速。
过去,银河系模拟总要在分辨率和规模之间妥协。现在,我们终于能一颗一颗地看清家乡星系的完整一生。这不只是计算上的胜利,更是理解宇宙化学演化、恒星诞生和元素起源的关键一步。未来,这样的混合模拟会越来越常见,让天体物理进入真正的高精度时代。
原文: acm